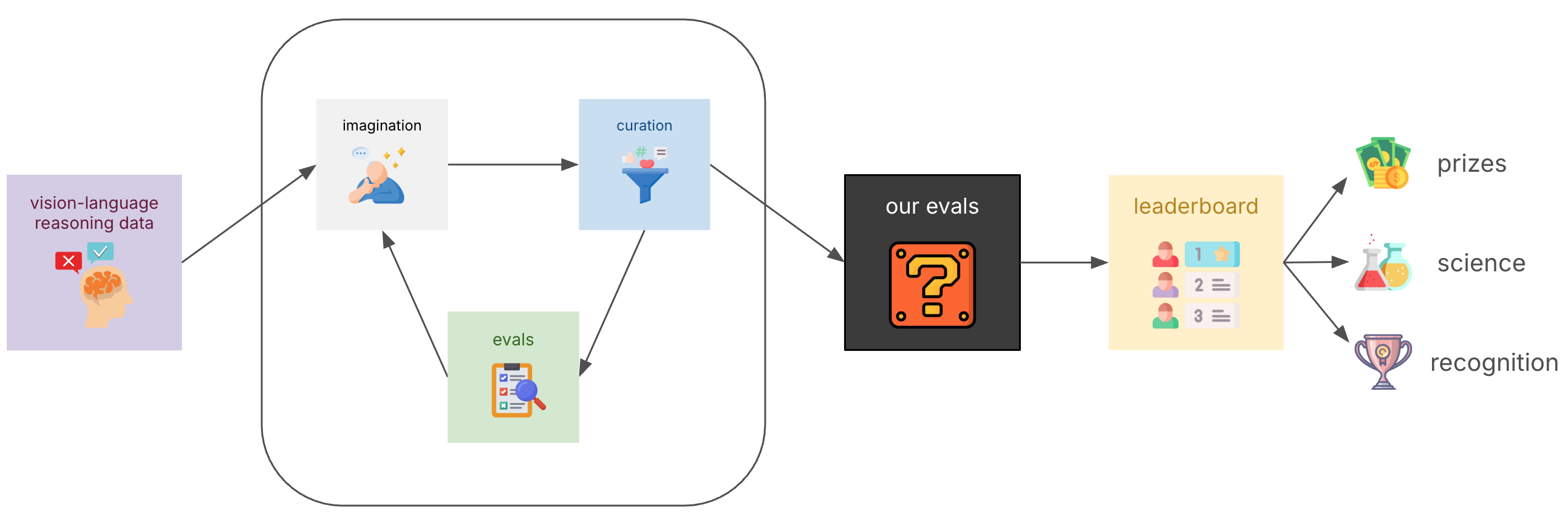
AI’s next leap hinges on reasoning—and vision-language models are the new frontier. While models like DeepSeek-R1 and GPT-o1 have brought reasoning to the forefront, progress in visual reasoning has been slower to catch up.
That’s exactly why the Data Curation for Vision-Language Reasoning (DCVLR) competition at NeurIPS 2025, sponsored and organized by Oumi and Lambda, matters.
We’re challenging researchers, engineers, and enthusiasts to do something novel: curate a compact, high-impact dataset that helps a small vision-language model (less than 10B parameters) reason better. You’ll bring your own data—sourced from HuggingFace or elsewhere—and create a dataset that elevates performance through fine-tuning.
You won’t just select existing samples. You can synthesize, augment, or generate entirely new data. Your mission is to assemble a set of examples that enables a hidden model to achieve the best accuracy on an evaluation set. Although the evaluation datasets themselves aren’t going to be revealed (yet), successful entries will demonstrate improved reasoning capabilities on images of tables, diagrams and natural images.
Choose between two tracks:
This competition builds on the success of techniques seen in LIMO and S1—where small, high-quality instruction-tuning datasets led to outsized gains in reasoning performance.
The next breakthrough could be yours.
Plus, to help you get started:
Whether you’re in it for the prizes, the science, or just the fun—you’ll be helping shape the next generation of multimodal reasoning models.
DCVLR isn’t just another competition. It’s a new kind of challenge with three key innovations:
We’re limiting participation to 500 teams (1–20 members per team), so don’t wait!
👉 Register now on the DCLVR homepage and for more details on the rules
👉 Give us a ⭐️ on GitHub
👉 Dive into the starter kit and join our Discord community
Let’s find out just how far the right data can take us.
Contributors: Stefan Webb, Benjamin Feuer, Oussama Elachqar